Note
In this document, sizes are in power of 2. That is, eg, MB means MiB.
Having worked with Ceph clusters since 2018, I have met plenty caveats, issues and also, of course, plenty good usecases. I mostly used Ceph as a big storage for rarely-read data at the beginning, but since 2020 I used it also as a VM drive backend for a Proxmox Cluster or for an OpenStack cluster.
More recently, I entered into a weird situation where the idea was to spawn ZFS
on big RBD as vdevs in order to take benefit of some ZFS features while using
Ceph as a storage backend. It did not go as planned,
but I gathered multiple worthwile outputs from this attempt.
Why did you need a ZFS over a RBD ?
Why ceph ?
The main point was to be able to backup asynchronously around 10 filers relying
each on 60 to 130 TB ZFS storage backend. These filers were provisioned in a
way that made the ZFS quite efficient, b at the cost of ~50% of the storage.
Of course this volume of data needs to be backuped. To save costs, the idea was to buy a big load of hard drives and use cold-storage to backup the data.
As we needed snapshots and had multiple hosts, we needed asynchronicity.
Considering the budget and allocated backup machines, I had not that much of a choice if I wanted redundancy : I needed one storage cluster, and therefore Ceph was the best option.
Which backend?
We pondered different options.
CephFS/Rados GW with automation tooling
The first was to have a big CephFS which would store all filer’s datas in
different subdirectories. This sounded appealing as it’d mean to rely on a
totally different storage stack for the backups and for the ZFS filers.
It was raising multiple questions :
- What tool to transfer data? To avoid retransferring, we’d need something like
rsync. But it’d require either custom wrappers to enable parallel transfer (Ceph has a high latency and a very large bandwith, transferring files one by one is just not using it efficiently). Alternatively, one could use rclone and its massively parallel design. - If working in this direction we need to transfer snapshots (to guarantee
data integrity), so use
zfs snapshotcalls, then mount the snapshots readonly and then transfer the data. Fine but how do we manage increments on the receiving side? - An option is
CephFSsnapshots, but the documentation is scarce at best, and prod-readiness is challengeable. We’d still need to design and test an automation mechanism to spawn subdirectory snapshots and then synchronize the data. - How do we handle increments retirement? How do we check data integrity?
In a whole, on the performance + stack variation stance this seemed as the best choice, but the tooling around it would be quite big to design.
In the same vein, we could just use a CephFS as a big storage landing point
and use a FOSS backup software (the requirement excluded any non-free
commercial backup system) like borg, backuppc etc.
Most of these software don’t do massively parallel transfer and do not stream data in a way which would avoid Ceph latency as a bottleneck.
Some newer backup solutions like restic do
exist, but they seem still quite young. Regarding
rclone, it is S3-compatible,
and therefore if the Ceph storage was to be exposed via a Rados Gateway, then maybe we could benefit from the best of all worlds.
We’d still need to automate some stuff on the filers, but it could be a proper solution.
One of the big con on this mechanism would be that the space occupation would be less optimal. As cold storage is cheap, it’s not really this bid of a deal, but it has to be kept in mind.
ZFS on RBD
At some point, I also suggested that we could test a ZFS receiving end on a
RADOS Block Device. The main reason is that ZFS comes with very efficient
way to transfer a snapshot to a receiving end, and in a way which almost
guarantees data integrity.
There are also plenty tools online which do already the backup automation. See for example zfs-autobackup. So if we could tune performances properly it could be our all-in-one solution requiring far less work to achieve a better result.
But the thing is, the Internet already contains lots and lots of reports of people having tried out to no avail.
But I’m the kind of dude willing to jump on a mine, so here goes.
In this article I’ll only talk about my findings on this matter, as the idea is
to give a bit more insights about why in general it’s a bad idea and what
people should consider before trying it out. If I were to recommend an option,
I’d use a proper backup suite on a CephFS or RGW backend. This tends to
give better outcome when relying on a Ceph cluster.
What’s the deal with ZFS over RBD?
Any person having tried or browsed about it eventually must have meet the same
kind of problem. It is mostly described in its entirety on OpenZFS issue
3324. The situation is low
performances on ZFS using RBD as vdevs for their ZPool. People describe
different varieties of low, with some having speed under 3 MB/s and others
capping at 30 MB/s. But on the average, when one knows today’s hard drive
speeds, it’s low, especially considering that Ceph has
multiple disks in backend and therefore should offer a reasonable write performance.
An example
For my tests purposes, I spawned a 90 TB RBD device (yes, it’s big, but meh).
# rbd create --size 90T --data-pool data rbd_meta/test
Wait, --data-pool ?
Yes. Here in order to save space, I wanted to rely on erasure-coding for the
data (for the same level of redundancy, we only use twice the data space
compared to a 3-replicate mechanism). But for the metadata I wanted to stay
under replicated mechanism to keep benefit from omap (see this
documentation).
Therefore, I have a data data pool, which actually can also be used for
CephFS, and a rbd_meta metadata pool which is using 3-replication.
Then, let’s run a bench call
# rbd -p rbd_meta bench --io-type=write --io-total=10G test
[...]
elapsed: 51 ops: 2621440 ops/sec: 51400.78 bytes/sec: 200 MiB/s
As one can see, nice performances here.
Well, that’s almost all. As soon as I export it on a VM (same bench perfs, you’ll have to take my word on this), things become more complicated.
Setup
To run my ZFS bench, I created a ZPool on my VM’s RBD device, and then
snapshotted a ZFS dataset on another host, and coupled a zfs send and zfs
receive on these two hosts, using mbuffer as a pipeline (dedicated network,
don’t care about encryption).
Note that zfs-autobackup does this
neatly for you, the only caveat I met was the fixed chunk size which was not
appropriate on my network.
And this happens:
# zpool iostat -q 1
capacity operations bandwidth syncq_read syncq_write asyncq_read asyncq_write scrubq_read trimq_write
pool alloc free read write read write pend activ pend activ pend activ pend activ pend activ pend activ
--------- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- -----
test-pool 2.0G 90T 0 102 0 11.4M 0 0 0 0 0 0 0 39 0 0 0 0
test-pool 2.0G 90T 0 82 0 9.10M 0 0 0 0 0 0 0 48 0 0 0 0
test-pool 2.0G 90T 0 106 0 11.2M 0 0 0 0 0 0 0 48 0 0 0 0
test-pool 2.0G 90T 0 68 0 7.75M 0 0 0 0 0 0 0 47 0 0 0 0
test-pool 2.0G 90T 0 54 0 5.73M 0 0 0 0 0 0 0 49 0 0 0 0
test-pool 2.0G 90T 0 95 0 10.9M 0 0 0 0 0 0 0 39 0 0 0 0
test-pool 2.0G 90T 0 93 0 9.01M 0 0 0 0 0 0 0 49 0 0 0 0
test-pool 2.0G 90T 0 85 0 7.16M 0 0 0 0 0 0 0 49 0 0 0 0
test-pool 2.0G 90T 0 70 0 7.35M 0 0 0 0 0 0 0 47 0 0 0 0
Bad performances. And it goes all the way like this.
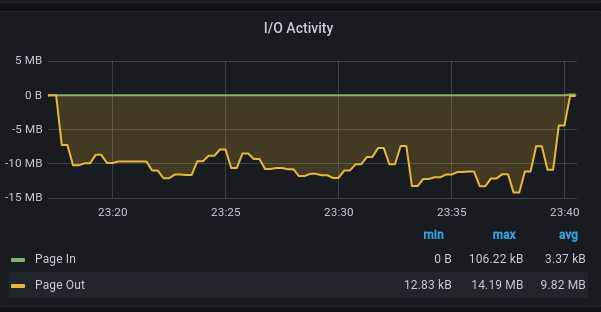
Boooooooooooooooooooooooo
There are multiple factors which explain that, but first, let’s see another iostat element:
# zpool iostat -r 10
[snip first output]
test sync_read sync_write async_read async_write scrub trim
req_size ind agg ind agg ind agg ind agg ind agg ind agg
-------- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- -----
512 0 0 0 0 0 0 0 0 0 0 0 0
1K 0 0 0 0 0 0 61 0 0 0 0 0
2K 0 0 0 0 0 0 142 0 0 0 0 0
4K 0 0 0 0 0 0 135 0 0 0 0 0
8K 0 0 0 0 0 0 58 0 0 0 0 0
16K 0 0 0 0 0 0 65 0 0 0 0 0
32K 0 0 0 0 0 0 130 0 0 0 0 0
64K 0 0 0 0 0 0 189 0 0 0 0 0
128K 0 0 0 0 0 0 451 0 0 0 0 0
256K 0 0 0 0 0 0 0 0 0 0 0 0
512K 0 0 0 0 0 0 0 0 0 0 0 0
1M 0 0 0 0 0 0 0 0 0 0 0 0
2M 0 0 0 0 0 0 0 0 0 0 0 0
4M 0 0 0 0 0 0 0 0 0 0 0 0
8M 0 0 0 0 0 0 0 0 0 0 0 0
16M 0 0 0 0 0 0 0 0 0 0 0 0
--------------------------------------------------------------------------------------------
Let’s try to explain what’s happening.
The recordsize delta
On ZFS filesystems, one of the properties of a dataset is the recordsize.
According to the
documentation,
it is the basic unit of data used for internal copy-on-write on files. It can
be set as a power of 2 from 512 B to 1 MB. Some software tend to use
fixed record size, and therefore if they use a ZFS as a backend, it’s a good
idea to set the dataset’s recordsize to the same value.
The default value is 128 KB, which is supposed to be a proper compromise for
default usage. The recordsize can be changed, but it will only impact newly
written data.
The thing is, Ceph‘s RBD default object size is 4
MB. It’s tuned that way because Ceph is a
hight-latency high-bandwith high-parallel storage system.
ZFS driver parameters tuning
While reading the OpenZFS issue
3324 I found that some people had
some performances increase by applying the following driver tuning on the zfs
kernel driver
I tried to poke a bit and arrived there (to no avail, but, still):
options zfs zfs_vdev_max_active=512
options zfs zfs_vdev_sync_read_max_active=128
options zfs zfs_vdev_sync_read_min_active=64
options zfs zfs_vdev_sync_write_max_active=128
options zfs zfs_vdev_sync_write_min_active=64
options zfs zfs_vdev_async_read_max_active=128
options zfs zfs_vdev_async_read_min_active=64
options zfs zfs_vdev_async_write_max_active=128
options zfs zfs_vdev_async_write_min_active=64
options zfs zfs_max_recordsize=8388608
options zfs zfs_vdev_aggregation_limit=16777216
options zfs zfs_dirty_data_max_percent=50
options zfs zfs_dirty_data_max_max_percent=50
options zfs zfs_dirty_data_sync_percent=20
options zfs zfs_txg_timeout=30
Let’s try to explain these options a bit.
options zfs zfs_vdev_max_active=512
options zfs zfs_vdev_sync_read_max_active=128
options zfs zfs_vdev_sync_read_min_active=64
options zfs zfs_vdev_sync_write_max_active=128
options zfs zfs_vdev_sync_write_min_active=64
options zfs zfs_vdev_async_read_max_active=128
options zfs zfs_vdev_async_read_min_active=64
options zfs zfs_vdev_async_write_max_active=128
options zfs zfs_vdev_async_write_min_active=64
The ZFS I/O Scheduler has 5 I/O classes which are all assigned to a queue: sync
read, sync write, async read, async write, scrub read (in decreasing priority order).
The ZIO scheduler selects the next operation to issue by first looking for an
I/O class whose minimum has not been satisfied. Once all are satisfied and the
aggregate maximum has not been hit, the scheduler looks for classes whose
maximum has not been satisfied. Iteration through the I/O classes is done in
the order specified above. No further operations are issued if the aggregate
maximum number of concurrent operations has been hit or if there are no
operations queued for an I/O class that has not hit its maximum. Every time an
I/O is queued or an operation completes, the I/O scheduler looks for new
operations to issue.
Here we chose a balanced profile as anyway most operations will be writes. We
set the min to 64 to reduce latency (setting it to 128 = max would be fine,
though, as writing in bursts is not an issue), and set the max to the
/sys/class/block/rbd0/queue/nr_requests value for a RBD => 128. Sometimes the
sum of operations will exceed 128 (if some read requests are enqueued, too),
but it’s marginal, and the impact on performance will be minimal, and not frequent.
options zfs zfs_max_recordsize=8388608
Allows to set a recordsize of 8MB for a ZFS dataset. Creating large
blocks increase the throughput, the cost being that a single modification of the 8 MB block triggers the writing of 8 MB. In the situation of a backup
system, we issue sequential writes using zfs receive, and therefore are not
really exposed to that issue. Of course we’d need to change the recordsize of the ZFS dataset to this value.
options zfs zfs_vdev_aggregation_limit=16777216
Aggregates small I/Os to one up to 16 MB large I/O to reduce IOps and increase
throughput (useful because hard drives used here are HDD).
options zfs zfs_dirty_data_max_percent=50
options zfs zfs_dirty_data_max_max_percent=50
dirty_data_max_percent determines how much of the RAM can be used as a dirty
write cache for ZFS.
options zfs zfs_dirty_data_sync_percent=20
options zfs zfs_txg_timeout=30
ZFS updates to its in-memory structures are done through transactions. These
transactions are aggregated in transaction groups (TXG). A TXG has three
potential states: open (when it accepts new transactions), quiescing (the state
it remains into until all open transactions are complete), and syncing (when it
actually writes data on-disk). There’s always one open TXG, and there’s at most
3 active TXGs. Transitions from open to quiescing are dictated by either a
timeout (txg_timeout) or a space “limit” (dirty_data_sync or
dirty_data_sync_percent). Therefore these parameters dictate that a TXG can
stay open up to the first of 30 seconds delay or 20% RAM written into it.
The main idea here was to rely on write aggregation in order to issue 4MB
writes to Ceph.
Sadly, the zpool iostat -q 10 in the setup part shown that
aggregation does not occur.
An attempt at understanding why the tuning doesn’t work and to circle over the issue
The main finding here is that most of the optimizations I made are designed to
work when write aggregation occur. Sadly, write aggregation do not occur. I
have not had time to run more specific tests, so I don’t know if this is due to the vdev being a RBD of if the lack of aggregation would also occur on a classic vdev. That being said, I was not able to have async write aggregation
working on a RBD vdev.
Independently of this matter, it seems that zfs receive is not multi-threaded
and therefore can’t issue concurrent writes. This means that we lose
performances on two sides : only 1 thread to write on the vdev, and no aggregation.
One could be tempted to change the receiving dataset’s recordsize so that the
write ops are of a bigger size, but the way zfs receive is designed makes it
use the incoming stream’s recordsize for write operations. Therefore, if the originating ZFS uses a 128 KB recordsize, then the destination’s highest
recordsize for written data will be 128 KB (see
this
discussion or this issue).
That being said, I was curious to see what would happen if the originating
snapshot was using a closer-to-4MB recordsize.
I therefore tried to rerun the upwards commands and benchmark the results with
4M B recordsize and 1 MB recordsize:
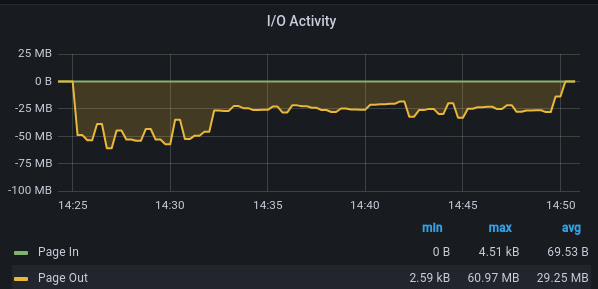
4 MB recordsize: 25 MB/s throughput
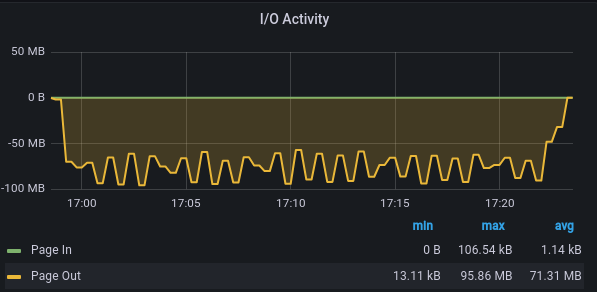
1 MB recordsize: 70 MB/s throughput
In both cases, no write aggregation was issued either, but as the recordsize
was significantly higher than 128 KB, the sequential writes on the storage
cluster were closer to the object size and therefore taking advantage of its
high bandwith.
The plus here is that even when scaling this backup workflow on multiple VMs
each one hosting its own RBD and receiving data from different originating
ZFS with proper recordsize, then the write performance stays high, until the
cumulated perf goes beyond what Ceph can handle.
Conclusion
As expected, performances are not really there, and the ZFS over RBD stack
as a backup mechanism is not really the good way to go if one expects high
write performances.
That being said, should people be aware of the pros and cons, if that fits
their needs, then it’s a way to take benefit from zfs send/zfs receive as
a backup mechanism.
In a whole, there are multiple tests to run and questions to tackle in order to understand better what is happening:
- Is
zfs receivealways relying on individual writes? (ie test it in other situations/VMs/configs to see what goes) - Considering a
ZFSover aRBDfor direct writes (notzfs receive), does aggregation occur? Although it’s not relevant for the backup usecase evoked here, it would be interesting to know if the issue is tied tozfs receiveof if it’s due toRBDas avdev. - If at some point the feature mentioned in this issue comes out, see if the performance increases.
- The performance is bad on
zfs receiveusecase, but let’s assume that aZVOLis created on theZFScreated over theRBD, and the filesystem created on theZVOLis able to multithread writes, then depending on the value of/sys/module/zfs/parameters/zvol_threads, would the write performance be higher?
I have not spent more time on this matter because I was in need to advance on my backup solution, but surely if at some point I find some time, I’ll try to see through it and update this post depending on the findings.